
In the beginning there was spam. Cheap, unpersonalised, mass-sent junk mail, easily defeated by simple Bayesian Filters. Over the years spammers improved and an arms race between spammers and spam filters was started. Spam was to me never more then a minor nuisance, and when gmail was launched, all of google’s might was put into the race and spam in your inbox became virtually extinct. Now I don’t even remember what a “ch3aP V1agrA” email looks like.
Does this mean my inbox is empty? No. In fact I feel I receive more unwanted mail than ever. With the internet being more and more intertwined in our lives, we drop our email addresses with more and more companies, whom in turn have started sending “promotions”, and “updates” more and more frequent. Even though they usually contain an “unsubscribe” option which I sometimes spend some time clicking through, these mailing lists have become a bigger source of irritation than spam ever was.
This Jupyter Notebook started out as a way to regularly delete all “Newsletter spam” from my inbox. It turned out however, to be a lot more fun to dig through my gmail inbox, which is what this post is mostly about. I would recommend everyone reading this to clone this notebook and start the same journey on your own inbox. Viewing stats on my inbox is not that interesting, viewing the same stats on your own inbox? A completely different story. It also gives you a sense on how big mailing list spam has become. Although the Gmail API has a delete option - it went against my Data Scientist instinct to actually delete anything.
Let’s start with all required imports:
import httplib2
import os
import base64
import numpy as np
import pandas as pd
import datetime
import logging
import time
import matplotlib.pyplot as plt
import seaborn as sns
from typing import Union, Any, List, Optional, cast
from googleapiclient.discovery import build
from google_auth_oauthlib.flow import InstalledAppFlow
from google.auth.transport.requests import Request
%matplotlib inline
sns.set()
Connect to the Gmail API
To get our emails, we will use the Gmail API. To do this we first need to enable the Gmail API and download a credential file. In this case I have stored the credential file next to the jupyter notebook. Follow steps 1 and 2 on this page to enable the API and get the credential file.
First we need to connect to the Gmail api with the credentials file and build a “Resource” object:
SCOPES = ['https://www.googleapis.com/auth/gmail.readonly']
flow = InstalledAppFlow.from_client_secrets_file(
'credentials.json', SCOPES)
creds = flow.run_local_server()
service = build('gmail', 'v1', credentials=creds)
This object called service has a set of functions to connect to the API service. The following lists all the labels in my inbox, and is a good test to see if our connection works
labels = service.users().labels().list(userId='me').execute()
[label['name'] for label in labels['labels']]
['Deleted Items',
'Sent Items',
'[Imap]/Sent',
'CATEGORY_PERSONAL',
'Receipts',
'IMPORTANT',
'Travel',
'CHAT',
'SENT',
'INBOX',
'TRASH',
'DRAFT',
'SPAM',
'STARRED',
'UNREAD',
'Personal',
'CATEGORY_FORUMS',
'CATEGORY_SOCIAL',
'[Imap]/Trash',
'Work',
'CATEGORY_UPDATES',
'CATEGORY_PROMOTIONS']
Loading our data
To download all our emails we can use the get function. This function needs an email id as input. To get these IDs we need the users.messages.list method. The following function returns a list with all email id’s belonging to a specific label (e.g. Inbox, Spam, Sent, etc):
def list_messages_with_labels(service, user_id, label_ids=[]):
response = (service
.users()
.messages()
.list(userId=user_id,
labelIds=label_ids).execute())
messages = list()
if 'messages' in response:
messages.extend(response['messages'])
while 'nextPageToken' in response:
page_token = response['nextPageToken']
response = (service
.users()
.messages()
.list(userId=user_id,
labelIds=label_ids,
pageToken=page_token).execute())
messages.extend(response['messages'])
return messages
For the purpose of this post we are just interested in messages in my inbox:
all_email_ids = list_messages_with_labels(service, 'me', 'INBOX')
print(f'I have {format(len(all_email_ids), ",d")} messages in my inbox')
I have 37,950 messages in my inbox
Single events can be retrieved using the get function which returns a dictionary:
event = (service.users()
.messages()
.get(userId='me', id='168480e9f32d4068')
.execute())
To parse the output from the mentioned get function, I’ve created a small “Email” class which takes the email dictionary as the input of its constructor, and has the parts of the email we are interested in as its attributes. I’ve added type hints in case this is ever taken out of this notebook and put into a module.
class Email(object):
def __init__(self, email: dict):
self._logger = logging.getLogger('Email')
self.id: str = email['id']
self.label_ids: List[str] = email.get('labelIds', None)
self.date: datetime.datetime = datetime.datetime.fromtimestamp(int(email['internalDate'])/1000)
self.size: int = email['sizeEstimate']
self.sender: str = None
self.to: str = None
self.subject: str = None
if 'headers' in email['payload']:
self._parse_headers(email)
else:
self._logger.warning(f'Headers not found for email with id: {self.id}')
self.__dict__ = self._as_dict()
def _parse_headers(self, email: dict):
headers = email['payload']['headers']
for header in headers:
if header['name'] == 'From':
self.sender = header['value']
elif header['name'] == 'To':
self.to = header['value']
elif header['name'] == 'Subject':
self.subject = header['value']
def _as_dict(self):
return {k: v for k, v in self.__dict__.items() if not k.startswith('_')}
Now we can fetch a list of emails and convert this to a DataFrame. As we don’t want to send and get a new http request for each email we will use the BatchHttpRequest object. This object allows us to bundle multiple http requests and a callback function that handles the result of the individual requests. The gmail API is rate limited at 250 requests per second - so we will have to create batches of 250 or less requests, and wait one second after each batch request is executed.
BATCH_SIZE = 200 # Maximum number of requests per second
emails = list() # List of Dictionaries with the emails
def add_emails(request_id, response, exception):
"""Callback function that handles the result of each request"""
if exception is not None:
# Do something with the exception
raise ValueError(exception)
else:
# Convert the email to a dictionary using our Email class
emails.append(vars(Email(response)))
batch = service.new_batch_http_request()
for i, msg_id in enumerate(all_email_ids):
batch.add(service
.users()
.messages()
.get(userId = 'me', id = msg_id['id'])
, callback=add_emails)
if i % BATCH_SIZE == 0:
batch.execute()
batch = service.new_batch_http_request()
print(f'{i} out of {len(all_email_ids)} done')
time.sleep(2)
# Create a DataFrame from our list of emails
all_emails = pd.DataFrame(emails)
37900 out of 37950 done
Exploring our data
Let’s have a look at our newly created DataFrame:
all_emails.head()
| date | id | label_ids | sender | size | subject | to | |
|---|---|---|---|---|---|---|---|
| 0 | 2019-02-09 19:01:42 | 168d4b5b42e4c21d | [IMPORTANT, CATEGORY_SOCIAL, INBOX] | Quora Digest <digest-noreply@quora.com> | 120030 | Why do so many software engineers/ programmers... | me@gmail.com |
| 1 | 2019-02-09 17:15:08 | 168d45420f87bb57 | [UNREAD, CATEGORY_UPDATES, INBOX] | Glassdoor Jobs <noreply@glassdoor.com> | 35059 | An opportunity for you at Trupanion was just p... | me@gmail.com |
| 2 | 2019-02-09 16:28:03 | 168d42909cef9597 | [UNREAD, CATEGORY_PERSONAL, INBOX] | ns-vertraging@ns-vertragingsmail.com | 5494 | LET OP: Je trein is geannuleerd | me@gmail.com |
| 3 | 2019-02-09 14:59:03 | 168d3d788dcfc077 | [UNREAD, CATEGORY_PERSONAL, INBOX] | ns-vertraging@ns-vertragingsmail.com | 5493 | LET OP: Je trein is geannuleerd | me@gmail.com |
| 4 | 2019-02-09 14:45:03 | 168d3caba6a335bd | [UNREAD, CATEGORY_UPDATES, INBOX] | ns-vertraging@ns-vertragingsmail.com | 5486 | LET OP: Je trein is geannuleerd | me@gmail.com |
We can now use this DataFrame to dig through our emails. For example calculate the total size of our inbox in gigabytes:
all_emails['size'].sum() / 1024 ** 3
4.190045651048422
Or find out the biggest email in our inbox - in this case a 34MB email with pictures from a Rafting trip in 2011. Fun times!
all_emails[all_emails['size'] == max(all_emails['size'])]
| date | id | label_ids | sender | size | subject | to | sender_norm | anon | |
|---|---|---|---|---|---|---|---|---|---|
| 22077 | 2011-10-22 19:36:15 | 1332dff678ef6b13 | [CATEGORY_PERSONAL, INBOX] | Some guy | 35686503 | Rangitata Rafts Pics | Me | Some guy | Some guy |
This is an obvious outlier - most emails are much smaller:
# Add a column with sizes in Mb - which is easier to read
all_emails['size_mb'] = all_emails['size'] / 1024 ** 2
_ = plt.hist(all_emails['size_mb'],
bins=[0, 0.05, 0.1, 0.2, 0.3, 0.5, 0.8, 1])
print(f'The median size is only {(all_emails["size"].median() / 1024):.2f} kb')
The median size is only 15.03 kb

Now lets see who our most frequent senders are. First we want to clean up the addresses a bit and strip out only the actual email address:
all_emails['sender_norm'] = (all_emails['sender']
.str.extract('<?(\S+@\S+.\w+)>?', expand=False)
.str.lower()
.str.replace('"', '')
.str.replace('<', '')
.str.replace('[', ''))
To see who the top senders are we can group by this new column and calculate the number of emails received from this person (count) and the total size of all emails sent by this person (sum of size_mb)
top_senders = (all_emails.groupby('sender_norm')
.agg({'sender_norm': ['count'], 'size_mb' : ['sum']})
.sort_values(by=[('sender_norm', 'count')], ascending=False))
# Check the 10 senders that send most emails
top_senders.head(10)
| sender_norm | size_mb | |
|---|---|---|
| count | sum | |
| sender_norm | ||
| ns-vertraging@ns-vertragingsmail.com | 1374 | 6.865120 |
| digest-noreply@quora.com | 960 | 95.993297 |
| info@meetup.com | 730 | 41.120080 |
| Family | 697 | 185.316703 |
| notification+orpefvl1@facebookmail.com | 695 | 6.315460 |
| Friend 1 | 657 | 48.461307 |
| Friend 2 | 650 | 88.133715 |
| Wife | 628 | 231.473106 |
| Newsletter 1 | 586 | 20.304824 |
| Newsletter 2 | 517 | 213.101904 |
I’ve anonymised most of the senders for obvious reasons. I’m glad to see there are some friends and family members in the top 10, and it’s not only newsletters. My number 1 spammer: ns-vertraging@ns-vertragingsmail.com is an automated mail I get when the train I used to take gets delayed, see this previous blog post. As you can see, this train is delayed a lot… It’s also good to know that the newsletters are generally much smaller than the emails from friends. If we sort by size we see mostly natural persons in the top 10, me sending myself emails with large attachments being number 1.
top_senders.sort_values(by=[('size_mb', 'sum')], ascending=False).head(10)
| sender_norm | size_mb | |
|---|---|---|
| count | sum | |
| sender_norm | ||
| me@gmail.com | 378 | 300.656649 |
| Wife | 628 | 231.473106 |
| Newsletter 2 | 517 | 213.101904 |
| Family | 697 | 185.316703 |
| Friend 3 | 196 | 122.931810 |
| Sports club | 231 | 97.326284 |
| digest-noreply@quora.com | 960 | 95.993297 |
| Friend 4 | 43 | 94.249075 |
| Friend 2 | 650 | 88.133715 |
| Friend 5 | 57 | 81.848216 |
Emails over time
Let’s calculate the amount of emails received per week. First we need to change the index of the DataFrame to the date column:
all_emails = all_emails.set_index('date')
Now we need to resample the DataFrame in weekly periods, and count the number of emails per week. To get a nice and smooth line we will use a rolling average of these counts. To calculate the means we use a gaussian kernel (the function that is used to take the average of the neighboring points).
weekly_counts = all_emails.resample('W').count() # Get a count per week
# filter data from before gmail existed
weekly_counts = weekly_counts[weekly_counts.index > np.datetime64('2004-04-01')]
# Calculate the moving average
moving_av = weekly_counts.rolling(10, center=True, win_type='gaussian').mean(std=3)['id']
Now plot this moving average. I’m using the Object Oriented interface of Matplotlib which gives you much more flexibility and and ease of use in the long run.
fig, ax = plt.subplots(figsize=(20,8))
ax.set(xlabel='Date', ylabel='Weekly Count',
title='Emails recieved per Week')
_ = moving_av.plot(ax=ax)
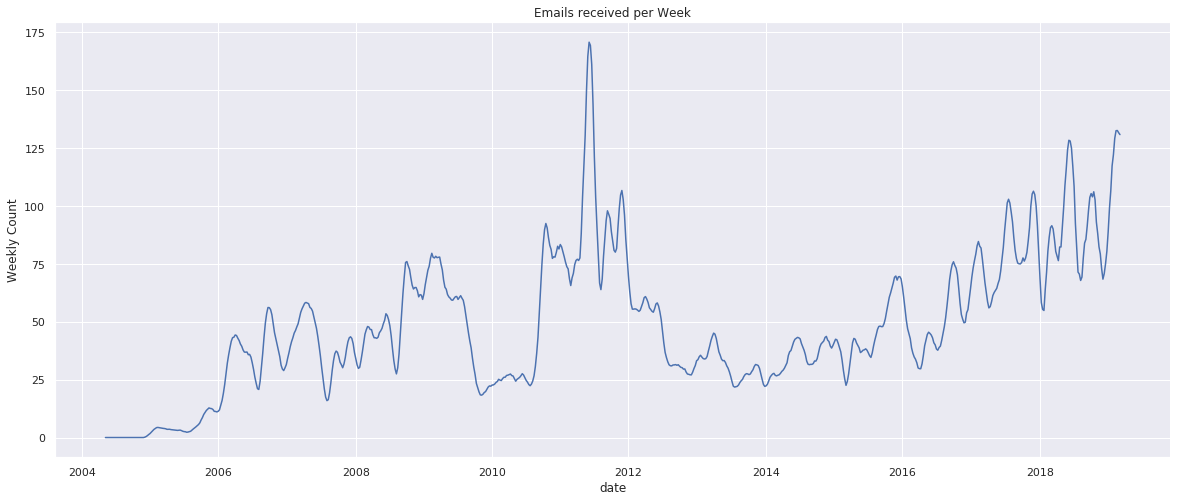
Very cool! For the reader this might be “just” a graph, which is why I recommend to clone this notebook and run it on your own data. For me I see a clear period when I was in university, a period when I was not in university and using another email address, a period when I was basically using gmail as a substitute for what is now WhatsApp, and the rise of newsletter spam.
# Filter only emails from the 15 frequent senders:
top_sender_over_time = all_emails[all_emails['sender_norm'].isin(top_senders.head(15).index)]
# Group by sender and month and count
top_sender_over_time = (top_sender_over_time
.groupby(['sender_norm', pd.Grouper(level='date', freq='M')])
.agg({'sender_norm': ['count']}))
# "Unstack" the sender part of the index, so each sender gets his own column
top_sender_over_time = top_sender_over_time.unstack(level='sender_norm')
# Resample to make sure all periods have a value, even when no emails were recieved in that period
top_sender_over_time = top_sender_over_time.resample('M')
# Calculate the moving average the same way we did before
top_sender_over_time = (top_sender_over_time.sum()
.rolling(10, center=True, win_type='gaussian')
.mean(std=3)
)
Our columns now are a MultiIndex with three levels, the first two having just a single value each (‘sender_norm’, and ‘count’). We can remove these to get a cleaner looking plot:
top_sender_over_time = top_sender_over_time['sender_norm']['count']
Let’s plot it!
fig, ax = plt.subplots(figsize=(20,8))
ax.set(xlabel='Date', ylabel='Weekly Count',
title='Emails recieved per Week')
_ = top_sender_over_time.plot(ax=ax)

To be honest, it looks like someone threw a plate of spaghetti on my screen… Let’s put it in something a little bit more readable, such as a heatmap. We can do this with the excellent Seaborn heatmap function. We can use this on our DataFrame directly, or transpose our DataFrame to get one where the senders are on the Y-axis and dates on the X-axis:
top_sender_over_time_t = top_sender_over_time.transpose()
top_sender_over_time_t.columns = top_sender_over_time_t.columns.strftime('%Y-%m')
Now create the heatmap:
def plot_heatmap(df_to_plot, xlabel, ylabel, title):
"""Plots heatmap based of df_to_plot with some extra formatting"""
fig, ax = plt.subplots(figsize=(25,10))
ax = sns.heatmap(df_to_plot, ax=ax, xticklabels=True, cmap="RdBu_r")
# I only want to see 1/5th of the orignal x axis labels for better readabilty
xticks = ax.get_xticks()
xtick_labels = ax.get_xticklabels()
x_labels = [label for i, label in enumerate(xtick_labels) if i % 5 == 0]
_ = ax.set_xticks([x for i, x in enumerate(xticks) if i % 5 == 0])
_ = ax.set_xticklabels(x_labels)
# The following formats the labels on the x-axis to be more readable
_ = fig.autofmt_xdate()
# Set axis labels and title
_ = plt.ylabel(xlabel)
_ = plt.xlabel(ylabel)
_ = ax.set_title(title)
plot_heatmap(top_sender_over_time_t, 'Sender', 'Date', 'Emails recieved per Month')
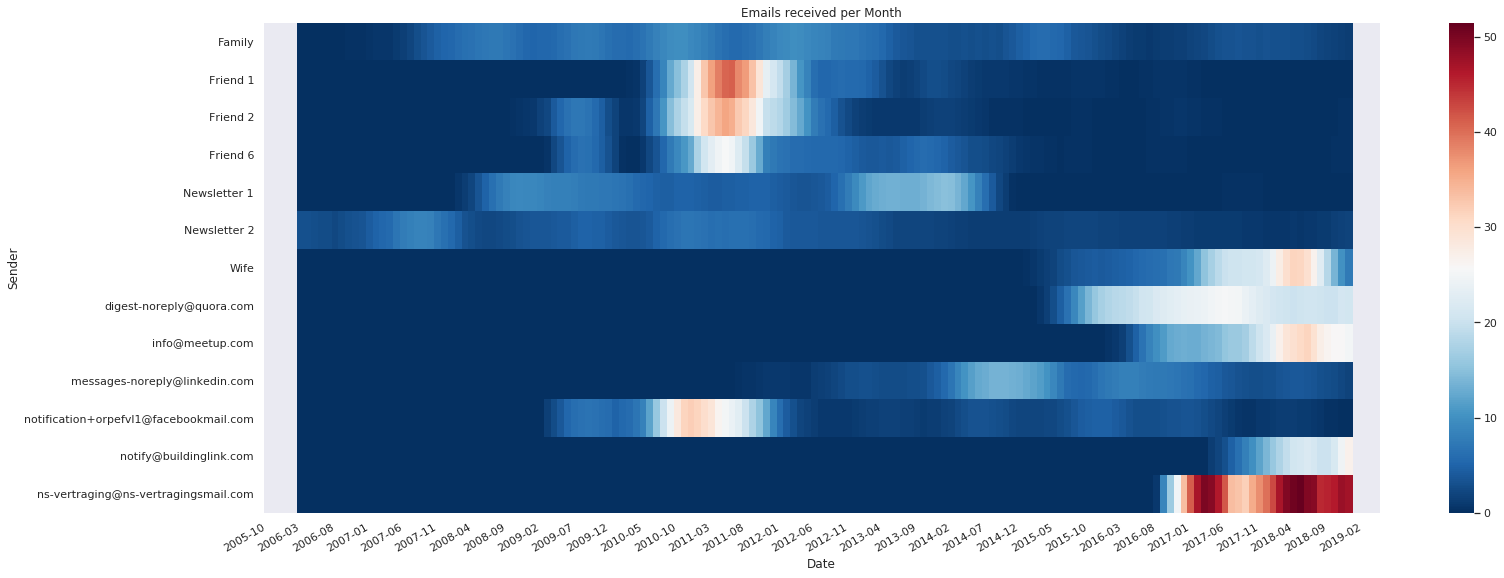
This looks a bit nicer, its easy to see when the hotspots were for certain senders and how they correlate. The downside of this plot is that the absolute numbers are harder to read.
Newsletter spam
Now back to the original subject - how much of the email in my inbox comes from maillinglists, or “newsletter spam”? Since 2010 Google started adding labels to each email which do a pretty good job at classifying the different types of email. The different categories an email can have are “forums”, “personal”, “social”, “promotions”, and “updates”. Out of these 5 options, the only category I would not consider spam are the personal emails.
Building a DataFrame
First I delete the ns-vertragings mail. Its not fair to call this newsletter spam, as its basically something I send myself using a cron-job. Its also being mislabeled by gmail alot.
all_emails = all_emails[all_emails.sender!='ns-vertraging@ns-vertragingsmail.com']
Each email can have multiple labels. We need to “explode” these into a new dataframe with one row for each label
labels_over_time = pd.DataFrame(all_emails.label_ids.apply(pd.Series, 1).stack())
labels_over_time.columns = ['label']
labels_over_time = labels_over_time[labels_over_time.index.get_level_values('date') > np.datetime64('2004-04-01')]
As you can see, the labels are now shown in a “long” format, with multiple labels per email:
labels_over_time.head()
| label | ||
|---|---|---|
| date | ||
| 2019-04-06 05:02:13 | 0 | UNREAD |
| 1 | CATEGORY_UPDATES | |
| 2 | INBOX | |
| 2019-04-06 00:59:27 | 0 | UNREAD |
| 1 | CATEGORY_UPDATES |
On this data we’ll do the same as we did before on all emails: group by month and get the counts for each label, resample and calculate the rolling average. After that we transpose to get the months as columns and the categories as rows:
labels_over_time_cnt = (labels_over_time
.groupby(['label', pd.Grouper(level='date', freq='M')])
.agg({'label': ['count']})
.label
)
labels_over_time_cnt = (labels_over_time_cnt
.unstack(level='label')
.resample('M').sum()
.rolling(10, center=True, win_type='gaussian')
.mean(std=3)
)
labels_over_time_cnt = labels_over_time_cnt['count']
labels_over_time_cnt_t = labels_over_time_cnt.transpose()
labels_over_time_cnt_t.columns = labels_over_time_cnt_t.columns.strftime('%Y-%m')
# Keep only the category labels
labels_over_time_cnt_t = labels_over_time_cnt_t[labels_over_time_cnt_t.index.str.startswith('CATEGORY')]
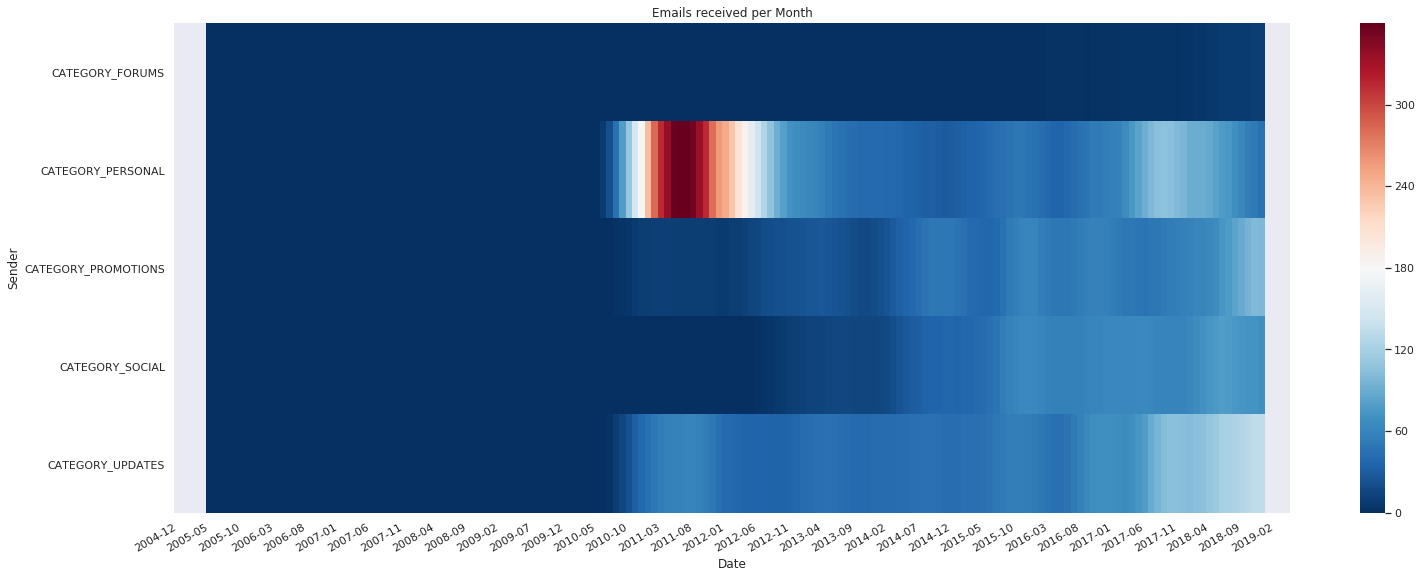
plot_heatmap(labels_over_time_cnt_t, 'Sender', 'Date', 'Emails recieved per Month')
fig, ax = plt.subplots(figsize=(20,8))
ax.set(xlabel='Date', ylabel='Weekly Count',
title='Emails recieved per Week')
_ = labels_over_time_cnt.filter(like='CATEGORY', axis=1).plot(ax=ax)

I think it’s clear that the number of updates, promotions and social media updates are growing fast. The actual numbers are hard to gauge as I’ve been consistently inconsistent in clearing my inbox of these type of emails.
Deleting events
I’ll leave the actual deletion as an exercise for the reader. You can batch delete messages with:
service.users().messages().batchDelete(userId=user_id, body={
"ids": [ # The IDs of the messages to delete.
"A String",
],
}).execute()