Finding similar strings within large sets of strings is a problem many people run into. In a previous blog Super Fast String Matching I’ve explained a process of finding similar strings using tf-idf and the cosine similarity.
The process however leaves you with a long list of similar strings, whereas in my experience you often want a one-to-one mapping of an original string to a new string. In other words, you want to group similar strings together, and pick one single string as the identifier for each group. To solve this I’ve created a small module called: string_grouper.
string_grouper
string_grouper does the following things:
- Match similar strings within a single series of strings or between two series of strings. This is what was shown in the blog.
- Group similar strings within a single series of strings. Each group gets a single string assigned as group identifier.
- Match only the most similar string within two series of strings, a master series and a duplicate series. For each string in duplicates the most similar string in master is returned. If there are no strings above the threshold, the original duplicate string is returned.
Installation and Examples
To install:
pip install string-grouper
Examples
Examples can be found on git:
- Find all matches within a single dataset
- Find all matches in between two datasets
- For a second dataset, find only the most similar match
- Deduplicate a single dataset and show items with most duplicates
How it works
All functions are build using a StringGrouper object. The StringGrouper takes either one (master)
or two (master and duplicates) pandas series of strings as input. To build the StringGrouper the
fit function is called. Once the StringGrouper is fit it calculates the tf-idf matrices for
either only the master or both the master and duplicates. After these matrices are calculated
it calculates the dot product between the two matrices. In case of only a master Series, it calculates
the dot product of the matrix and its own transpose. Since the dot product is the same as the cosine
similarity for normalized matrices (e.g. a tf-idf matrix), this results in a sparse matrix of
cosine similarities. Only the similarities above a certain threshold (default: 0.8) are stored.
This sparse matrix is translated to a DataFrame of matches. On the left side the index of a string is given from the master Series, and on the right side the index of a string in the duplicate series. If there is no duplicate Series, the index is also that of a string in the master Series.
Using this DataFrame it is trivial to get all matches (this can be done using the get_matches function),
or to get the most similar item in master of a set of duplicates (using the get_groups function).
Get Groups
If the get_groups function is called on a StringGrouper with only a master Series of strings a
single linkage clustering approach is used to get a single identifying string for each group. This works
as follows:
- Make sure each item matches with itself.
- For each string index, find the lowest other string index that is a match, this will be the group id.
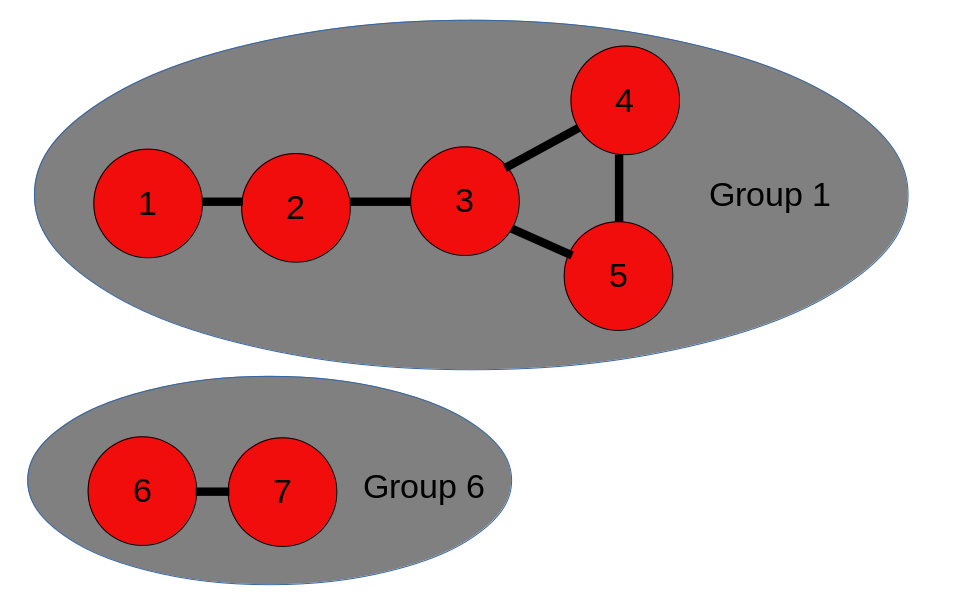
- Some groups will be orphaned - the group id will not be in the group itself. See for example in the image below. Here the strings with index 4 and 5 will get group id 3. The string with index 3 however, will get group id 2 since it’s the lowest match.
- To solve this, the group id of the index that has the id of the group id of the orphaned group is taken and assigned to the orphaned group. In the image below this means that the group with group id 3 will get renamed to group id 2.
- This is repeated until no more orphaned groups exist. In the image below you can see the end-result, all items (1 - 5) have group id 1. Items 6 and 7 get group id 6.
- The strings with the same indices as the group id’s are returned. The result is a Series with the same length as the master Series.